
In my previous write-up, I alluded somewhat nebulously and with flowery language to vaguely specified development “difficulties” caused by the fact that Replay’s implementation relies on partial determinism. In this one, I aim to step away from generics and get down to the technical brass tacks of what that difficulty looks like.
Observe & Report
Let’s look at the crash-fix development flow that arises out of Replay’s design and implementation. It’s kind of weird, and starts here:

The Honeycomb query we use to visualize recent crashes
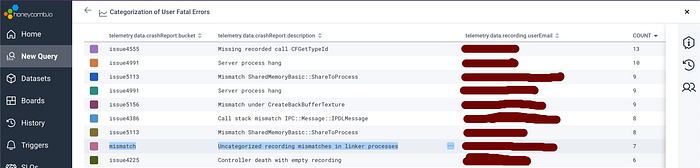
An example of some results (sans emails)
We make heavy use of Honeycomb to gain insights into what’s happening within our system. I don’t have time or space to talk about Honeycomb here, but let me tell you that it’s amazing. A huge chunk of our internal metrics and telemetry filter through this service and we depend on it heavily.
Whenever a recording is viewed, our backend does extensive logging of what occurred during the session. These logs are saved, and then processed by a triaging script that analyzes them for reports coming from crashes in the Replay browser. The triaging log processor emits a metadata-annotated log entry to Honeycomb for any crashes that it notices.
Each of the lines in the screenshot above represents a particular type of crash that was encountered by some user. The unfortunate user at the top of this list has experienced 13 crashes because their replaying session encountered a call to
CFGetTypeId, a recorded API call, that wasn’t found in the encoded recording stream. The triage script determined this by looking at the stack traces included in the crash report, and has identified that this type of crash is associated with issue 4555.Why did this crash happen for this user? Because the replay diverged from the recording in some way, and ended up in a place where the replaying code tried to read a recorded call that wasn’t present in the recording stream.

Uncategorized mismatches suffered by one of our users
On the second to last line (see above) we see a different type of entry: an uncategorized mismatch. This is a crash where the replaying process expected to read some entry from the recording stream, but the entry it read didn’t match what it expected. Furthermore, the triaging system was unable to pattern-match the details of this crash, so it’s a new unknown type of crash and isn’t bucketed under any preexisting GitHub issue.
All of these divergences between replaying and recording are due entirely to the fact that we rely on partial determinism at the low level to deliver effective determinism at the high level. [link]. If it wasn’t for that, none of this infrastructure would need to exist, and life would be so much simpler, so boo partial determinism! But as I mentioned in the previous article, Replay wouldn’t be able to work as smoothly as it does, so hooray partial determinism!
Categorize For Posterity
The next step is making sure our uncategorized errors are categorized. This is a priority because we have little hope of fixing these crashes if we aren’t able to track and group them.
Let’s take a look at an example of an uncategorized mismatch. Mismatches are crashes which the system induces whenever the replaying process encounters a recorded API call, and notices that the program state associated with the call during the recording doesn’t match the state during the replay’s consumption of that call. In this case, the mismatch that triggered the crash was a
RecordReplayAssert, which is a special recorded call we use to help track down replaying divergences.This is a real example, so I’ve edited out some information for the sake of user privacy:
json{ "Timestamp": "---", "event.date": "---", "message": "TelemetryEvent", "service_name": "telemetry-server", "telemetry.category": "ControllerFinished", "telemetry.data.buildId": "linux-gecko-20220209-ab89a0e652f6-8a592af1a0f7", "telemetry.data.buildMetadata.brand": "replay", "telemetry.data.buildMetadata.date": "20220209", "telemetry.data.buildMetadata.platform": "linux", "telemetry.data.buildMetadata.runtime": "gecko", "telemetry.data.controlId": "---", "telemetry.data.crashReport.bucket": "mismatch", "telemetry.data.crashReport.buildId": "linux-gecko-20220209-ab89a0e652f6-8a592af1a0f7", "telemetry.data.crashReport.controlId": "---", "telemetry.data.crashReport.description": "Uncategorized recording mismatches in linker processes", "telemetry.data.crashReport.linkerVersion": "linker-linux-8079-8a592af1a0f7", "telemetry.data.crashReport.process.backtrace": { "frames": [ "mozilla::detail::MutexImpl::lock()+11", "mozilla::image::SourceBuffer::Iterator(unsigned.long)+32", "mozilla::image::DecoderFactory::CreateDecoder(mozilla::image::DecoderType,.mozilla::NotNull<mozilla::image::RasterImage*>,.mozilla::NotNull<mozilla::image::SourceBuffer*>,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::image::DecoderFlags,.mozilla::image::SurfaceFlags,.mozilla::image::IDecodingTask**)+107", "mozilla::image::RasterImage::Decode(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool&,.bool&)+612", "mozilla::image::RasterImage::LookupFrame(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool)+640", "mozilla::image::RasterImage::RequestDecodeForSizeInternal(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.unsigned.int)+203", "mozilla::image::RasterImage::RequestDecodeForSize(mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.unsigned.int,.unsigned.int)+104", "nsImageFrame::MaybeDecodeForPredictedSize()+682", "mozilla::PresShell::UpdateImageLockingState()+233", "mozilla::PresShell::SetIsActive(bool)+177", "nsDocShell::ActivenessMaybeChanged()+139", "std::_Function_handler<void.(mozilla::dom::BrowsingContext*),.mozilla::dom::BrowsingContext::DidSet(std::integral_constant<unsigned.long,.2ul>,.mozilla::dom::ExplicitActiveStatus)::$_11>::_M_invoke(std::_Any_data.const&,.mozilla::dom::BrowsingContext*&&)+42", "mozilla::dom::BrowsingContext::PreOrderWalkVoid(std::function<void.(mozilla::dom::BrowsingContext*)>.const&)+62", ... ], "threadId": 1 }, "telemetry.data.crashReport.process.manifest": "runToPoint", "telemetry.data.crashReport.process.recorded": "OrderedLock image::SourceBuffer 1735", "telemetry.data.crashReport.process.recordedStack": [ "mozilla::detail::MutexImpl::lock()+11", "mozilla::image::SourceBuffer::Iterator(unsigned.long)+32", "mozilla::image::DecoderFactory::CreateDecoder(mozilla::image::DecoderType,.mozilla::NotNull<mozilla::image::RasterImage*>,.mozilla::NotNull<mozilla::image::SourceBuffer*>,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::image::DecoderFlags,.mozilla::image::SurfaceFlags,.mozilla::image::IDecodingTask**)+107", "mozilla::image::RasterImage::Decode(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool&,.bool&)+612", "mozilla::image::RasterImage::LookupFrame(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool)+640", "mozilla::image::RasterImage::RequestDecodeForSizeInternal(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.unsigned.int)+203", "mozilla::image::RasterImage::RequestDecodeForSize(mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.unsigned.int,.unsigned.int)+104", "nsImageFrame::MaybeDecodeForPredictedSize()+682" ], "telemetry.data.crashReport.process.replayed": "OrderedLock image::SourceBuffer 1740", "telemetry.data.crashReport.process.threadId": 1, "telemetry.data.crashReport.process.why": "Mismatch", "telemetry.data.crashReport.recordingId": "---", "telemetry.data.crashReport.why": "NoProgress", "telemetry.data.fatalError": true, "telemetry.data.recording.cleanedUrl": "---", "telemetry.data.recording.duration": 144548, ... }
A Crash Report for a Replay Mismatch
There’s a lot of detail here, but the key bits we care about are in the
recordedStack, recorded, backtrace, and replayed fields under telemetry.data.crashReport.process. We observe that the backtrace and recordedStack fields have effectively the same few frames at the top, indicating that the replay proceeded in sync with the recording under the nsImageFrame::MaybeDecodeForPredictedSize call. However, a mismatch occurred because a different lock (mutex) was acquired during replay than during recording, as evidenced by the difference between the recorded and replayed fields. The recorded lock being acquired was labelled image::SourceBuffer 1735, and the lock being acquired during replay was labelled image::SourceBuffer 1740.We can’t tell from this trace why specifically the locks being acquired are different, but our first task is to make sure we catch any future crashes that happen in this same way, so that we can track how many users are hitting this crash and how often they’re hitting it. It also helps us with outreach to users so we know who to contact when we fix this issue.
We do that by modifying our crash-categorization triage code to include a filter that matches crash reports against specific patterns. Here’s an example of what that looks like:
javascriptconst Filters: FilterFunction[] = [ // ... filterMismatch("issueXXXX", "Mismatch under RasterImage::LookupFrame", { text: "OrderedLock", stack: "RasterImage::LookupFrame", }), // ... ]; // Filters for linker mismatches based on the values involved. function filterMismatch( bucket: string, description: string, params: MismatchFilter ): FilterFunction { const { text, stack } = params; return (crashReport, process) => { if ( process.why == ProcessCrashReason.LinkerMismatch && (textMatches(text, process.recorded) || textMatches(text, process.replayed)) && (!stack || process.recordedStack?.some(f => f.includes(stack)) || process.replayedStack?.some(f => f.includes(stack))) ) { return maybeFixed(crashReport, params, bucket, description); } }; }
A filter for our mismatch
This filter is one of many within the triage script that we run on all crashes, and will ensure that future occurrences of a crash with
RasterImage::LookupFrame in the stack trace where the mismatch message contains OrderedLock will be correctly filed under a specific GitHub issue.Crash Better The Second Time Around
These crashes are difficult to debug directly. These divergence-based crashes can be intermittent, and even if they weren’t, they often come from user-made recordings which we don’t give ourselves the permission to replay, and even if we did get that permission, the infrastructure to directly debug a replay is something that’s difficult for various other reasons I can get into in a subsequent write-up.
But what we can do in the short term is to use this crash as a clue to add assertions so that future similar crashes occur at a point where we might get a better understanding of what’s going on.
In this case, it really seems like we’re getting a different
RasterImage, or possibly nsImageFrame (which contains the RasterImage) at this point of the replay when compared to the original recording. It seems like it’d be worthwhile to insert an explicit check somewhere higher up the call path, to ensure that the replay is working with the same underlying frame or image objects as the recording was at this point in the execution.This is what the program stack looked like in the replaying process when the mismatch occurred:
plain textmozilla::detail::MutexImpl::lock()+11 mozilla::image::SourceBuffer::Iterator(unsigned.long)+32 mozilla::image::DecoderFactory::CreateDecoder(mozilla::image::DecoderType,.mozilla::NotNull<mozilla::image::RasterImage*>,.mozilla::NotNull<mozilla::image::SourceBuffer*>,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.mozilla::image::DecoderFlags,.mozilla::image::SurfaceFlags,.mozilla::image::IDecodingTask**)+107 mozilla::image::RasterImage::Decode(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool&,.bool&)+612 mozilla::image::RasterImage::LookupFrame(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.mozilla::image::PlaybackType,.bool)+640 mozilla::image::RasterImage::RequestDecodeForSizeInternal(mozilla::gfx::IntSizeTyped<mozilla::UnorientedPixel>.const&,.unsigned.int,.unsigned.int)+203 mozilla::image::RasterImage::RequestDecodeForSize(mozilla::gfx::IntSizeTyped<mozilla::gfx::UnknownUnits>.const&,.unsigned.int,.unsigned.int)+104 nsImageFrame::MaybeDecodeForPredictedSize()+682 mozilla::PresShell::UpdateImageLockingState()+233 mozilla::PresShell::SetIsActive(bool)+177 nsDocShell::ActivenessMaybeChanged()+139 std::_Function_handler<void.(mozilla::dom::BrowsingContext*),.mozilla::dom::BrowsingContext::DidSet(std::integral_constant<unsigned.long,.2ul>,.mozilla::dom::ExplicitActiveStatus)::$_11>::_M_invoke(std::_Any_data.const&,.mozilla::dom::BrowsingContext*&&)+42 mozilla::dom::BrowsingContext::PreOrderWalkVoid(std::function<void.(mozilla::dom::BrowsingContext*)>.const&)+62 view raw
Stack trace in replaying process at mismatch point
It indicates that the call to
RasterImage::MaybeDecodeForPredictedSize is made by nsImageFrame::UpdateImageLockingState. Here’s the C++ code for that method:c++void PresShell::UpdateImageLockingState() { // We're locked if we're both thawed and active. bool locked = !mFrozen && mIsActive; mDocument->ImageTracker()->SetLockingState(locked); if (locked) { // Request decodes for visible image frames; we want to start decoding as // quickly as possible when we get foregrounded to minimize flashing. for (const auto& key : mApproximatelyVisibleFrames) { if (nsImageFrame* imageFrame = do_QueryFrame(key)) { imageFrame->MaybeDecodeForPredictedSize(); } } } }
Implementation of PresShell::UpdateImageLockingState
To try to catch this replay divergence “earlier”, it would be helpful to ensure that the image-frames being operated on are the same between record & replay.
So the next step is to add a “recording assertion” at this point, ensuring that the image frames we’re seeing during replay earlier in the execution is the same as what was recorded:
c++if (nsImageFrame* imageFrame = do_QueryFrame(key)) { recordreplay::RecordReplayAssert("PresShell::UpdateImageLockingState imageFrame=%p", imageFrame); imageFrame->MaybeDecodeForPredictedSize(); }
An example of a possible recording assertion
But wait! We can’t quite do that so easily. The addresses for specific runtime objects (the pointer-value of
imageFrame here) are not stable between recording and replays - which is to say that the “same” object can have different pointer addresses during recording and replaying. This recording assertion as it stands will probably cause an induced mismatch crash every time this code is hit. To get around this, we have some internal C++ infrastructure to track objects and give them stable ids between recording and replaying.So we need some prep work in the constructor and destructor of
nsImageFrame before we can assert the order of image frames seen at this point in the code. Let’s see what that looks like:c++nsImageFrame::nsImageFrame(ComputedStyle* aStyle, nsPresContext* aPresContext, ClassID aID, Kind aKind) : /* ...init */ { /* ...existing constructor code */ // Register nsImageFrame instance for tracking during // record/replay and give it a stable id recordreplay::RegisterThing(this); } nsImageFrame::~nsImageFrame() { // Unregister it when destroying recordreplay::UnregisterThing(this); }
Registering nsImageFrame instances with the recording
Now back to our code in the
PresShell::UpdateImageLockingState implementation. Here, we use a helper function called recordreplay::ThingIndex() to retrieve a stable number that identifies this object between both recording and replaying:c++if (nsImageFrame* imageFrame = do_QueryFrame(key)) { recordreplay::RecordReplayAssert( "PresShell::UpdateImageLockingState imageFrame=%u", recordreplay::ThingIndex(imageFrame)); imageFrame->MaybeDecodeForPredictedSize(); }
An improved example of a recording assertion
And that’s it. We land this code, ship it to release, and bide our time and await a better crash to come in via our Honeycomb dashboards, and then take a look at that crash to see if there’s some new information we can work with.
Since the Replay browser is a fork of firefox and open-source, I can link directly to the relevant GitHub pull request adding this assertion: https://github.com/RecordReplay/gecko-dev/pull/829
Tell Me There is a Better Way
If the above approach feels ad-hoc to you, I’m totally with you. This is an incredibly roundabout way of going about debugging issues. Like trying to catch a rabbit by progressively building smaller and smaller circles of fence around it.
We’d love to build better infrastructure for investigating these sorts of crashes. We’ve discussed different approaches for doing so, and have reached out to many colleagues to brainstorm different ideas.
We can modify our implementation to include more information in the recording stream itself (but only when recording internal tests, so that we don’t bloat production user-made recording sizes too much), and validating that during replay, to automatically catch divergences far earlier than manually-inserted asserts released to production.
We can try using classical “fully deterministic” record-replay using Robert O’Callahan’s original “rr” tool in linux to record our replays, and then replay the crashing replays in a deterministic way to directly debug divergences.
But doing all of this requires many heads, and we are a growing but small startup with a released product that’s in active use by customers and which requires active maintenance at the same time as being pushed forward. We have built a passionate and intelligent team of people to work on all the various aspects of our product. That said, we need even more if we’re going to find breathing room to do what we want to do, and what we will need to do to make Replay robust and ready for millions of users to use every day.
The implementation ideas I just sketched out require careful engineering by people who get excited by complex and novel systems work, who relish a challenge, and who can apply concepts across a wide range of systems-level concerns to engineer solutions to sophisticated problems. People to whom the words “software like this hasn’t been built before, and we’re still figuring out how to do it better” is a clarion call.
If you’ve read this far and find yourself excited by the challenges that I’ve just described, excited by the idea of working on software whose boundaries and full structure hasn’t been fleshed out yet, excited by the thought of having your hand in influencing the direction and engineering of this sort of thing, consider reaching out to us at hiring@replay.io. If you’re curious for more detail, join our Discord and stop by the #runtimes channel where we share our findings, new approaches, and other discussions.

