

Computer programs are largely deterministic. Programming languages and the machine code which they compile down to both have defined semantics, and when repeatedly run against the same initial state a program will do the exact same thing in lock step. Non-determinism can leak in and cause repeated runs of a program to behave differently in two ways:
- Programs can read additional inputs from the environment, for example from a file or network socket. Different runs can read different data, and the program will behave differently.
- Multi-threaded programs can be affected by different thread interleavings. If the OS kernel schedules threads differently then those threads can read and write data in different orders, and the program will behave differently.
If we record how this non-determinism affects the program’s behavior, we can replay the program from that recording and ensure it behaves the same way. Replay’s recorder is based on this idea. In this blog post we’ll describe how Replay records and replays these two types of non-determinism.
Environmental Inputs
The environment that a program runs in can be described in terms of its interface with that program. This interface defines the recording boundary: when replaying, everything the program did within the boundary will be re-executed, and the side effects from everything outside the boundary will be reproduced using the recording.
The interface which Replay uses for the recording boundary is the API between an executable and the system libraries it is dynamically linked to. When recording, all data produced by calls into these system libraries is captured and added to the recording. When replaying, instead of calling into these system libraries the data from the recording is replayed instead.
To understand this better, let’s consider an example. The C program below reads the first line from a file “hello.txt” and then prints it. We want to record what this does so that we can replay it later, reading and printing the same data even if the file doesn’t exist anymore.
c#include <stdio.h>int main(int argc, char** argv) { FILE* fp = fopen(“hello.txt”, “r”); char buf[256]; fgets(buf, sizeof(buf), fp); puts(buf); fclose(fp); return 0; }
When this is compiled to an executable file, that executable does not define
fopen, fgets, or any of the other functions used to interact with files. Instead, when that executable is loaded the operating system’s dynamic linker loads system libraries which define these functions, and updates references in the loaded executable so that they will call those functions in the system library. Each executable and library has tables describing the functions it exports and imports, which the linker reads to perform these updates.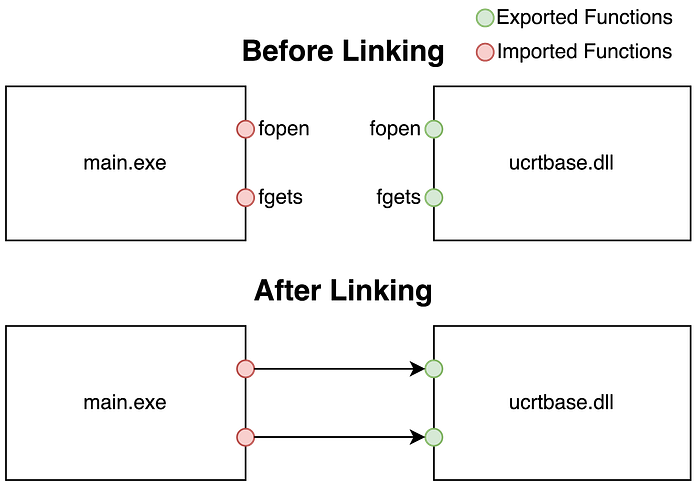
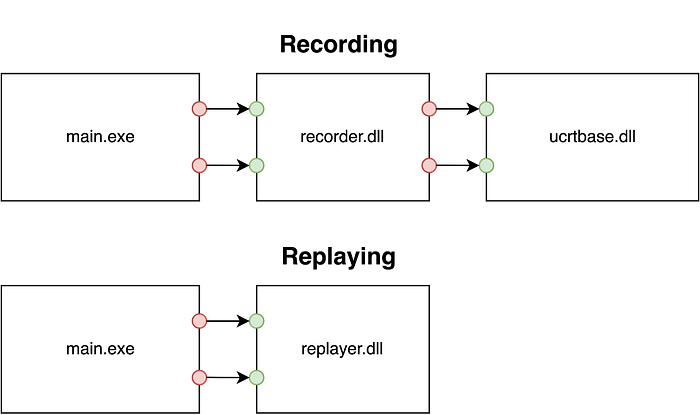
Replay’s recorder acts very much like the operating system’s dynamic linker. After an executable starts, if it wants to record its behavior it loads the recorder, which is a dynamically linked library. The recorder can read the executable’s import table, and after being loaded it changes outgoing references from the executable so that they will call functions defined by the recorder itself. These recorder functions are shims between the executable and the system libraries: when called, they collect the call’s inputs, call the original system library function with those inputs, collect the call’s outputs, and then return those outputs to the calling executable. The collected data is added to the recording, and the executable resumes execution, with no difference in behavior due to the presence of the recording shims.
Replaying works in a similar way. The executable which was used to make the recording is started, but instead of linking it to system libraries its imported references are updated to call functions defined by the replayer. When called, these functions look for a call with the same inputs in the recording, read the associated outputs from the recording, and return those outputs to the executable.
In the example above, when fgets is called while recording the data which the system’s fgets wrote to its buffer argument will be saved in the recording. When fgets is called while replaying then that buffer data will be read from the recording and written to the call’s buffer parameter. The system library’s fgets is outside the recording boundary and is not called when replaying, but because everything it did was saved while recording and restored while replaying, the executable will behave the same after the call and print the same data that it did when recording.
Recording at the system library call layer provides several benefits that make it the most practical choice for handling an assortment of operating systems and interpreted language runtimes:
- Since this interface is used by the system’s dynamic linker, it is easy to operate on (e.g. insert shims) without having to change code in the program being recorded. The executable file formats are different on each major operating system, but they are well documented, and long running projects like Wine and Darling use similar linker based techniques to run software in new environments.
- The system library call API is quite stable, as non-additive changes made between OS versions will break old software.
- Different programs running on an operating system all use the same system libraries, with the same APIs. While the programs can call different sets of functions within those libraries, there is a lot of overlap which simplifies the process of recording a new runtime.
Operating on library calls is enough to record some 99% or more of a program’s interactions with its environment, but it isn’t enough for everything. Other interactions like reading from memory shared with another process, or getting non-deterministic information directly from the CPU (such as the rdtsc instruction), will not go through a library call.
For cases like this the recorder library exports functions which can be used to directly record values so that they will be consistent when replaying, and to help track down sites where these calls are needed by reporting errors when values are inconsistent while replaying. Replay’s recorder only works in cooperation with the program being recorded: recordings made with an unmodified program that hasn’t been adapted to use the recorder will almost certainly fail to replay.
Having to adapt a new program to use the recorder makes it harder to start recording new runtimes, but gives the recorder the flexibility it needs to record programs of any complexity. This is especially important for multithreaded programs.
Multithreaded Programs
A multithreaded program can behave non-deterministically entirely due to different thread interleavings. Consider the following program, which creates several threads that fill up a buffer and then prints that buffer.
c#include <pthread.h> #include <stdio.h>pthread_mutex_t mutex; char buffer[51]; int bufferIndex;void* thread_main(void* ptr) { for (int i = 0; i < 5; i++) { pthread_mutex_lock(&mutex); buffer[bufferIndex++] = ‘a’ + (int)ptr; pthread_mutex_unlock(&mutex); } return NULL; }int main(int argc, char** argv) { for (int i = 0; i < 10; i++) { pthread_t thr; pthread_create(&thr, NULL, thread_main, (void*)i); } pthread_mutex_lock(&mutex); puts(buffer); pthread_mutex_unlock(&mutex); return 0; }
Compiling and running this program repeatedly prints different strings:
plain textaaaaabbbbbcccccdddddfffffeeeeehhhhhgggggiiiii aaaaabbbbbccccceeeeedddddfffffhhhhhgggggiiiiijjjjj abdcccecbeebbaaaaddddfffffggggghhhhhiiiiijjjjj abcaaaabbbbccccdddddeeeeehhhhhgggggfffffiiiii aaaaabbbbbcccccdddddfeefefggggghhhhhiiiii
This non-determinism happens because the order in which the different spawned threads fill in the buffer varies between different runs of the program. If we recorded and then replayed this program, its behavior while replaying would likely diverge from what happened while recording due to different interleavings.
This code pattern is similar to what happens in event loop driven programs like web browsers or the node.js runtime. When several threads are performing work and posting events to a shared queue on another thread, the order in which those events end up in the queue can vary between runs, affecting the program’s behavior in visible ways.
Replay’s recorder uses an ordered lock abstraction to record programs like this. An ordered lock is like any other lock or mutex, except that when replaying it will be acquired by different threads in the same order that it was acquired when recording. If we recorded the example above using an ordered lock instead of the unordered mutex variable, then when replaying the order in which threads write to the buffer will be the same as when replaying. Since each thread writes the same data between different runs, the buffer’s contents will be the same when it is finally printed.
This generalizes to any multithreaded program: if each thread gets the same values from the environment, and accesses to data shared between threads occur in the same order, then those shared data accesses will produce the same values and each thread (and the multithreaded program overall) will behave the same as it did when recording.
The recorder exports functions which can be used both to manipulate ordered locks directly, and to associate ordered locks with system resources like pthread mutexes, so that uses of that resource within library calls will be ordered the same when replaying. The latter APIs take care of most ordering within programs while requiring only minor code changes. Directly using ordered locks is still needed though when thread synchronization occurs without making library calls, such as when threads use atomic variables to signal each other.
An important aspect of this API is that system mutexes and other resources are by default unordered. In practice, we’ve found that most of these resources can be left unordered and the program will still do the same thing. Leaving these unordered reduces recording overhead and the recording size considerably, and it also allows certain parts of the program to behave differently when replaying. This is an important idea that is crucial for efficiently analyzing the program’s behavior while it is replaying. We explore this in more depth in the next blog post.

