


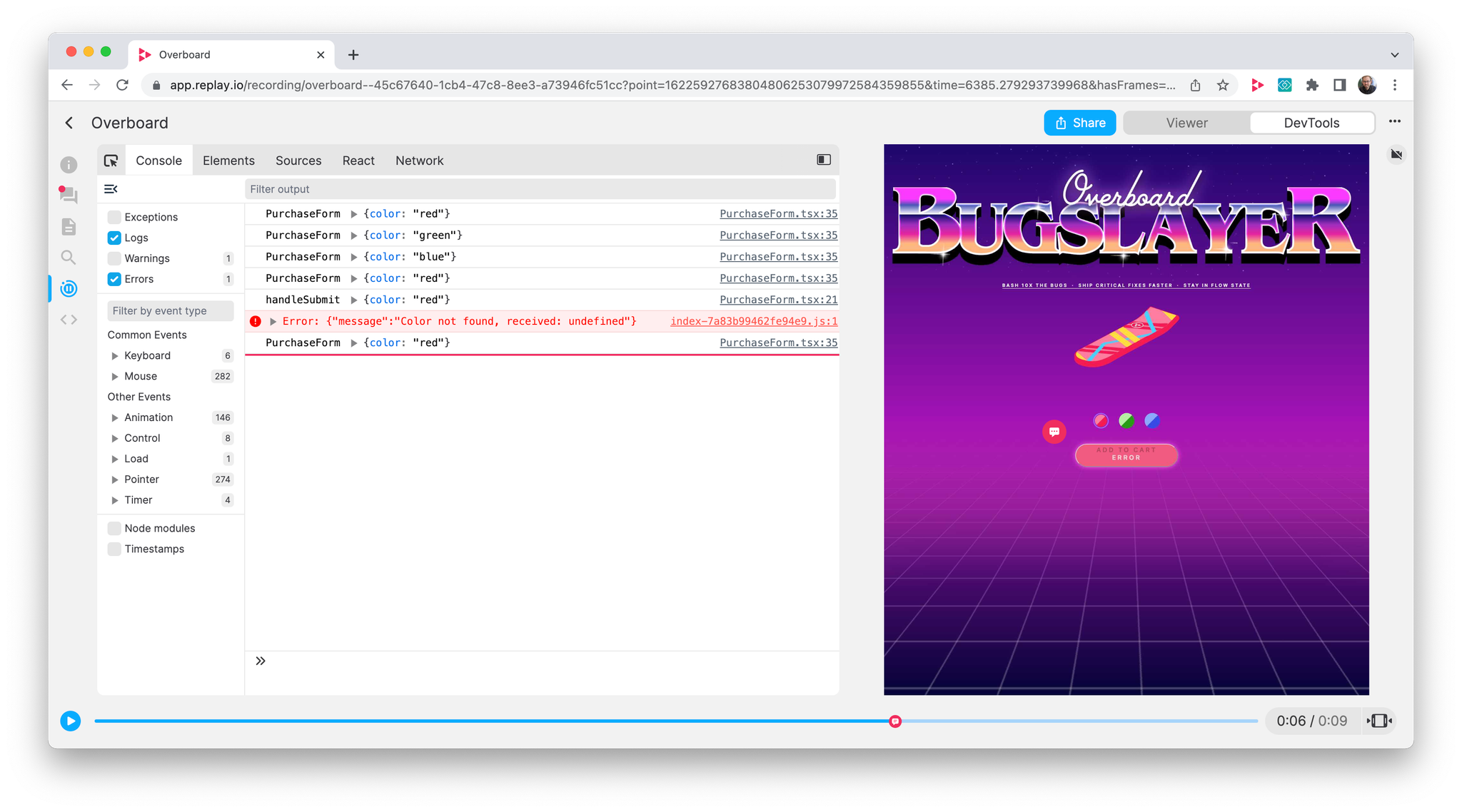
This week, we’re excited to share an update on Replay’s reliability and our plans to sweep up the remaining broken glass.
In January, one out of five debugging sessions would end in a crash. Today, less than one in thirty sessions crash. If you’d like to dig in, Kannan wrote a great series on how we diagnose crashes aka time travel divergences (1, 2).
In May, we started measuring a backend “butter score”. The idea was that every session would start with a perfect 100 score and we would subtract points when something bad happened. When we stated measuring, the median session was a 30. Today, it is an an 80 and we’re aiming for 100. When 90% of sessions have a perfect butter score, we will have swept up the broken glass.
There’s only so much that data can tell us though. Let us know what feels slow to you and we will fix it. Feel free to email us or hop into our Discord.
Backend Performance
We released two significant backend improvements which have been in the works for weeks.
The first is the Protocol Cache which lets us cache protocol requests so that they are only handled once. This is a big deal because most protocol requests require replaying a browser to a point in time. Today replaying performance is roughly linear, so helping the backend be lazier is a big deal.
The second performance improvement is JavaScript Scope Mapping. Without Scope Mapping, all the variables would be minified and print statements would not work. In the extreme case, scope mapping used to take 140 seconds. It now less than 14 seconds!
The next area we are looking into is resource allocation. A good way to think about our backend is, “What would it take to build CloudFlare Workers“? At a high-level, Replay is similar. When you start a debugging session, we start a browser. When you want to pause at a point in time, we run the browser to that point in time.
If that is not fun enough, we have also taught our browsers how to fork and snapshot themselves. This means that when you want to pause at second 72, there is likely a browser that is idling a couple of seconds away. And when you want to add a hot print statement, we fork many browsers, re-evaluate the expression, and return the results in under a second.
This works great in theory, but in practice it’s easy to overwhelm the system. That hot print statement could easily consume a hundred GBs of ram! And even though our nodes have a hundred cores, it’s easy to thrash them. We have some simple heuristics, but need to improve our observability in order to fine tune them.
New Console 🚀
We’re excited to release our new Console in a couple of hours 🚀 DevTools will now start faster, render smoother, and be more correct.
The Console showcases our new architecture which is built on top of React’s Suspense Cache. Suspense Cache is still very experimental, but Brian used Suspense Cache heavily while building React DevTools.
If you want to push the boundaries of what’s possible in the browser, you can’t beat it. Here’s a replay of the new Console in action and a video of Brian talking through how it works.
Frontend Architecture
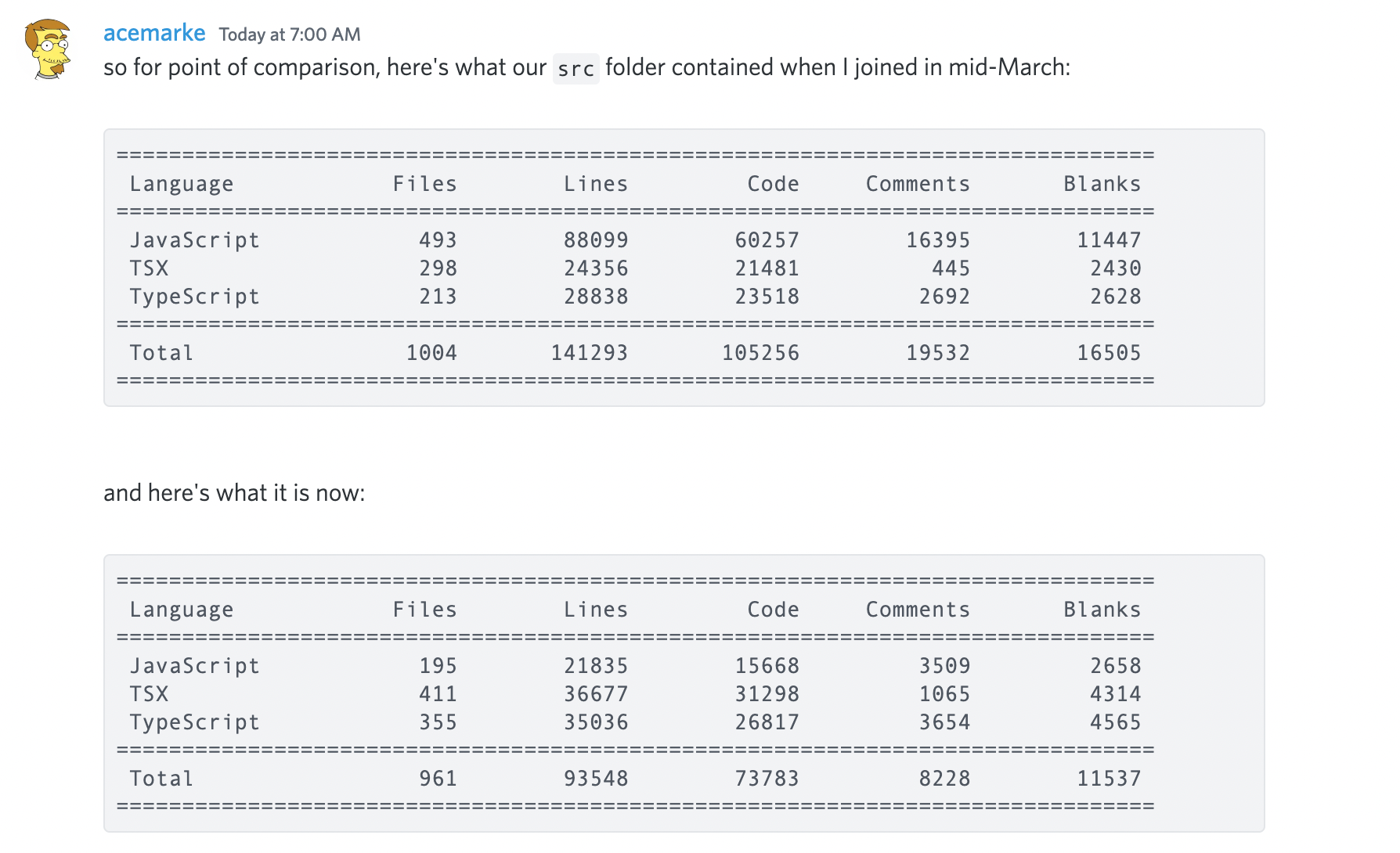
Mark is continuing to take a machete to our frontend codebase. The codebase is 33% smaller since joining and 90% of the code is typed. If you’d like to join in, reach out in our #frontend channel.
Additional Updates
Redux DevTools we disabled Redux DevTools temporarily when we discovered that Redux DevTools could in the extreme case request hundreds of MBs of application state from the backend.
When we revisit Redux DevTools this fall, we’ll ship a proper V1 that has a great timeline and works well across several state management tools.
Replay Feature
This week we’re excited to feature this PR that Mateusz opened to fix an issue we were seeing when we started using React’s new Offscreen API and Redux connect.
This is the second time Andarist (who is not on the team) has seen us discussing an issue on Twitter and taken a look at the replay and found the problem.
To put things in perspective, this is an exceptionally hard problem. Brian and Mark, who are React and Redux core maintainers, had already investigated and were stumped. Andarist was able to look at the replay and find the problem.
And because he did, Mark is now adding a fix to Redux which will help everyone who wants to use React’s Offscreen API with their Redux apps!