


Modern coding agents struggle to understand bugs in the apps they build. When an agent doesn’t know why a bug happens, its fix attempts often paper over the problem or break other parts of the app. The agent digs itself into a hole which it can’t easily get out of.
We’re releasing Web Debug Bench today, a benchmark that tests how good agents are at debugging agent-built web apps. We tested several frontier agents on 177 problems, here are overall results and the full report:
- 76%: Claude Code (opus-4.6) with Replay MCP
- 68%: Codex (gpt-5.4)
- 61%: Claude Code (opus-4.6)
- 48%: Gemini 3
All of these agents have room for improvement, whether or not they use Replay for time travel debugging. We’ll be using this benchmark to improve the debugging abilities of Replay enabled agents, and it will continue growing with more hard, realistic debugging problems.
You’re free to use this benchmark however you want. We’re happy to help with adapting or improving it for your testing or training needs, reach out if you want to chat.
Benchmark
Benchmark problems are simple and easy to test:
- Contents of a repository
- Playwright test failure error message
- Replay recording ID
- Answer key with an explanation of the root cause, associated source locations, and supporting evidence showing how the root cause leads to the test failure.
Given the repository contents, error message and (optional) recording, can an agent identify the location of the root cause and explain it? We judge responses both by checking for a valid location and using two judge LLMs (opus-4.6 and gpt-5.4) assess the agent’s explanation against the answer. They all agree about 80% of the time, which we’re working on improving.
The problems are all synthetic and generated automatically:
- We repeatedly run the Open Auto Builder to autonomously spec, build, and test complete web apps.
- Test failures the builder encounters are processed into problems.
- An agent uses Replay MCP to perform a root cause analysis on the problems to generate the answer key and validate it with two judge models (opus-4.6 and gpt-5.4).
This approach offers several advantages:
- Problems directly represent the actual bugs which agents write when building apps.
- Agents have never seen these apps before and have not trained on their source.
- Can automatically generate any number of apps and problems covering different stacks and categories of web apps.
- As agents improve, the difficulty of new benchmark problems scales to match their new limitations.
This is possible because of Replay MCP, which gives agents a time travel debugger for understanding everything that happened in the app, down to the finest detail. This additional context makes agents much better at understanding bugs. We leverage that understanding to build training materials and help future agents get better at fixing similar bugs, whether they are using Replay or not.
Results
We tested four agents by running each of them three times on 432 problems in the benchmark, producing an explanation of the test failure and a source location for the root cause. Results were scored pass/fail by the three judges. Agents score a point if all judges agreed they figured out the bug, and half a point if at least one judge agreed. We removed 255 easy problems that every agent consistently passed. Scores are below for the remaining 177 harder problems.
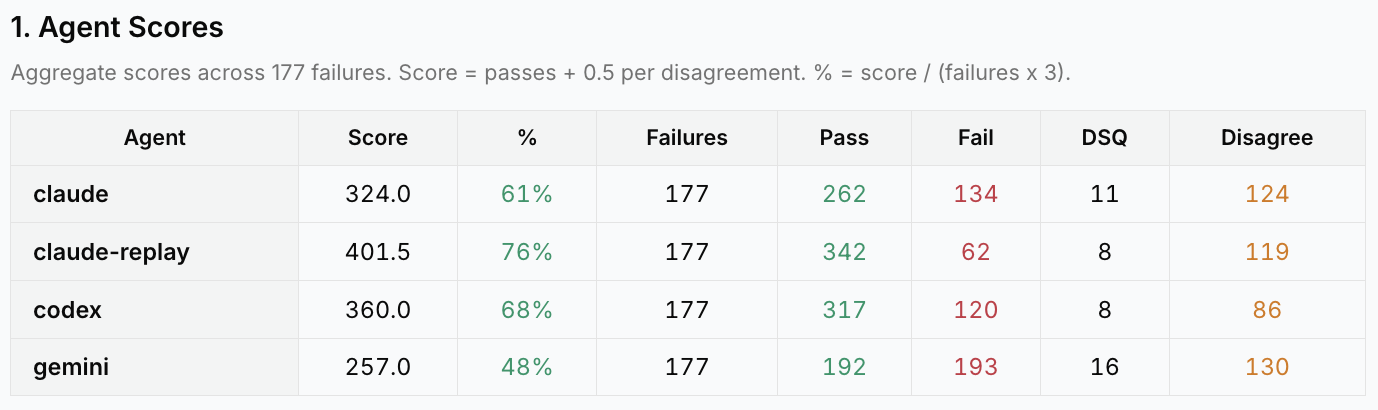
General assessments of the agents:
- Claude Code using opus-4.6 with access to Replay MCP and a recording of the test failure is the only agent that can do time travel debugging and outperformed the other agents. However, sometimes it jumped to conclusions and missed the actual root causes of the problems it looked at.
- Codex using gpt-5.4 did the best out of agents without access to Replay. These must figure out the problem using only the test error message and repository contents. Codex was consistently fast, often reading the test first and then related code from there in a targeted fashion. When codex fails it often quickly creates plausible-but-wrong theories about what happened, even when slower agents figured things out by reading the code.
- Claude Code using opus-4.6 is fast when it can spot the problem quickly, and spends quite a bit of time examining and thinking through things when the problem isn’t obvious. Often it hit a 30 minute timeout with nothing to show for it, but sometimes it was able to figure out tricky bugs like React race conditions or backend problems which Codex didn’t notice.
- Gemini did the worst at root causing failures. A common issue was starting by examining the backend code to look for problems instead of tracing execution back from the test code and frontend behavior. If the problem was actually in the frontend or test code the backend would be incorrectly blamed.
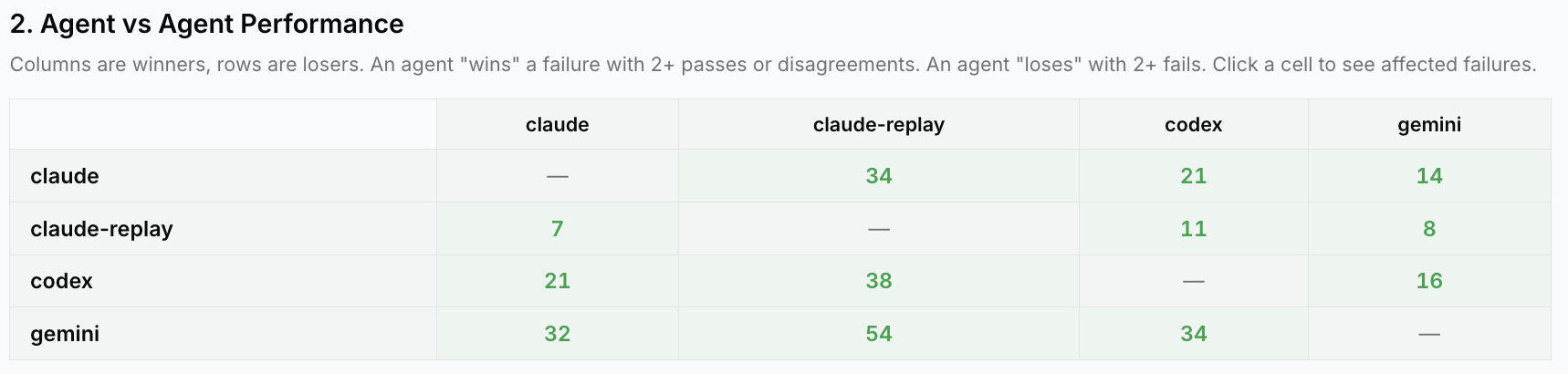
Despite these variations, there is no consistent pattern of winners across the individual problems. For every pair of agents there are problems where the first outperformed the second and the second outperformed the first (winner had 2+ pass/disagree and loser had 2+ failures). 98% of problems had at least one winner, and 89% had at least one non-Replay winner. For all these agents, the ceiling on their possible performance is well above where it is right now.
Example
Let’s look at the evaluation pipeline in detail for a single failure.
AB-9 captures a bug found while testing an auto builder app, VetRx, which is a treatment / prescription manager for a veterinary practice. The problem is a frontend React bug that overwrites data entered by the user with stale data from the server, so that when a user tries to set a treatment followup date it is not saved properly. A race condition causes the test to fail intermittently, making this challenging to debug.
The auto builder submitted this test failure to the benchmark with a repo URL, test file name, and failing changeset. From there the test failure goes through a couple preliminary stages:
- Cleaning: An agent takes the initial reproduction information, reproduces the test failure, and creates a new branch with a reproduction script.
- Refinement: An agent runs the reproduction script and gathers artifacts: the repository contents, error message, and a Replay recording of the failure.
Root Cause Analysis
An agent in a container then inspects the recording via MCP to understand and explain the root cause of the bug. The agent submits an explanation of the root cause, a list of source locations for the root cause, and supporting evidence – MCP call results and source snippets – tracing the test failure back to that root cause. Judge models review the explanation and evidence and must both accept them before the agent is finished.
This approach works reliably because of the level of detail the agent can provide in its evidence. For AB-9 the root cause explanation traces the entire lifecycle of the bug, showing the interleaved behavior of Playwright, the network, and various component and state management JS. This precision is only possible using Replay and lets judges make sure the bug has been completely described.

Testing
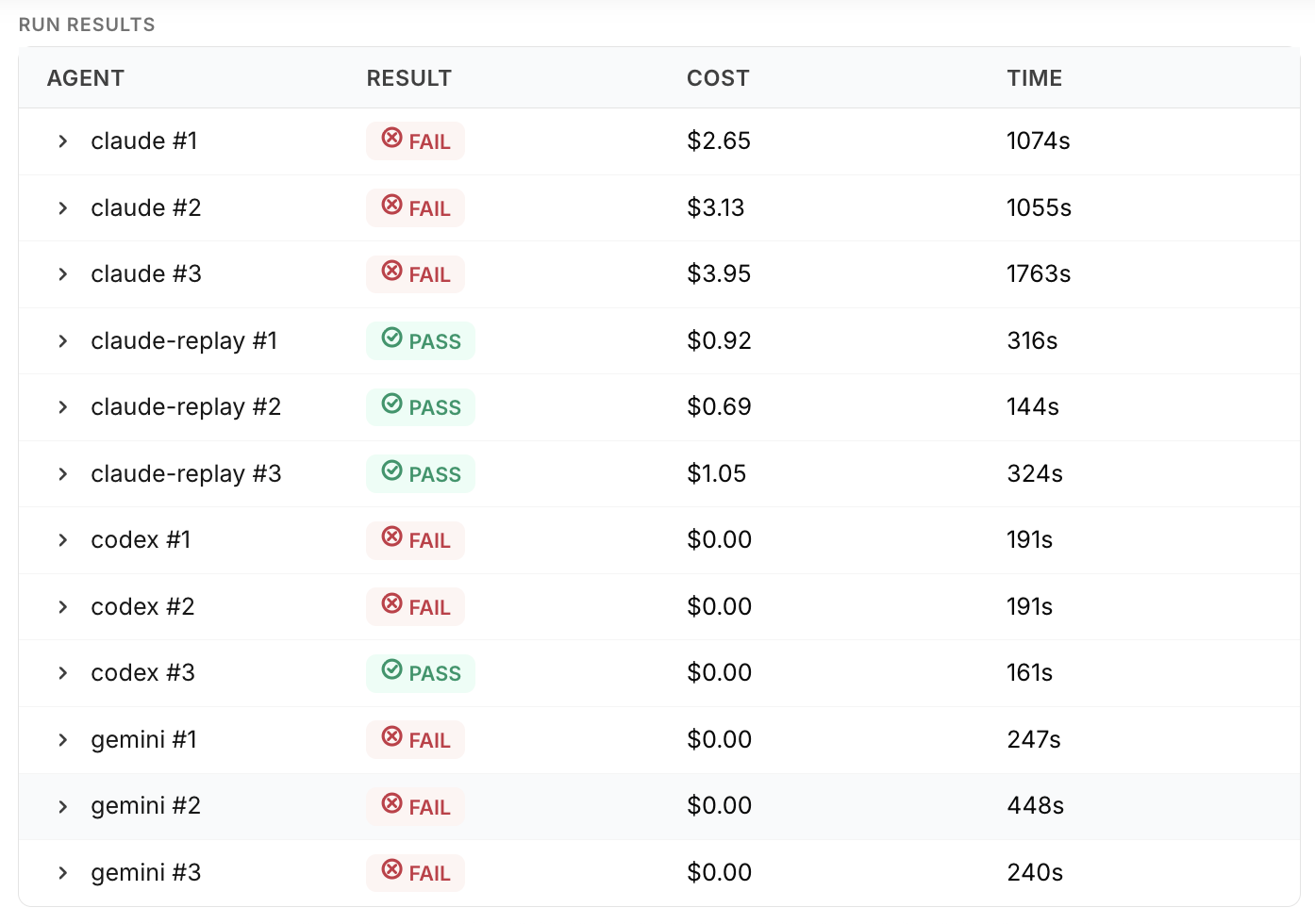
Each agent was tested three times each and each attempt was assessed by the three judges (two LLMs and a location comparison). For AB-9 every judge is in agreement about each attempt.
Claude using Replay is the only agent that consistently identified the React bug, taking 2-5 minutes each time. Codex identified the bug once, but the other two times it identified an incorrect root cause based on an unsupported theory about a backend problem breaking the test. Claude and Gemini failed every time, fixating on a similar theory about a backend problem.
Conclusion
Our results show that the context provided by Replay MCP’s time travel debugger greatly improves how well agents understand hard, realistic bugs in web apps. That increased understanding is key to automatically building benchmark problems which stress the limits of agents at debugging and which will evolve in sophistication as the agents themselves improve. Reach out if you’re interested in using Web Debug Bench for your testing or training needs.
